GigaGAN, an innovation in the field of GAN architectures

In the realm of deep learning models, Generative Adversarial Networks (GANs) have gained significant attention for their ability to generate synthetic data that resembles known data distributions. One notable GAN architecture that has captured the imagination of researchers and developers is GigaGAN. Developed by a collaborative team from POSTECH, CMU, and Adobe, GigaGAN is a state-of-the-art model specifically designed for text-to-image synthesis. In this article, we will explore the unique features and applications of GigaGAN, comparing it to other GAN architectures and discussing its open-source nature.
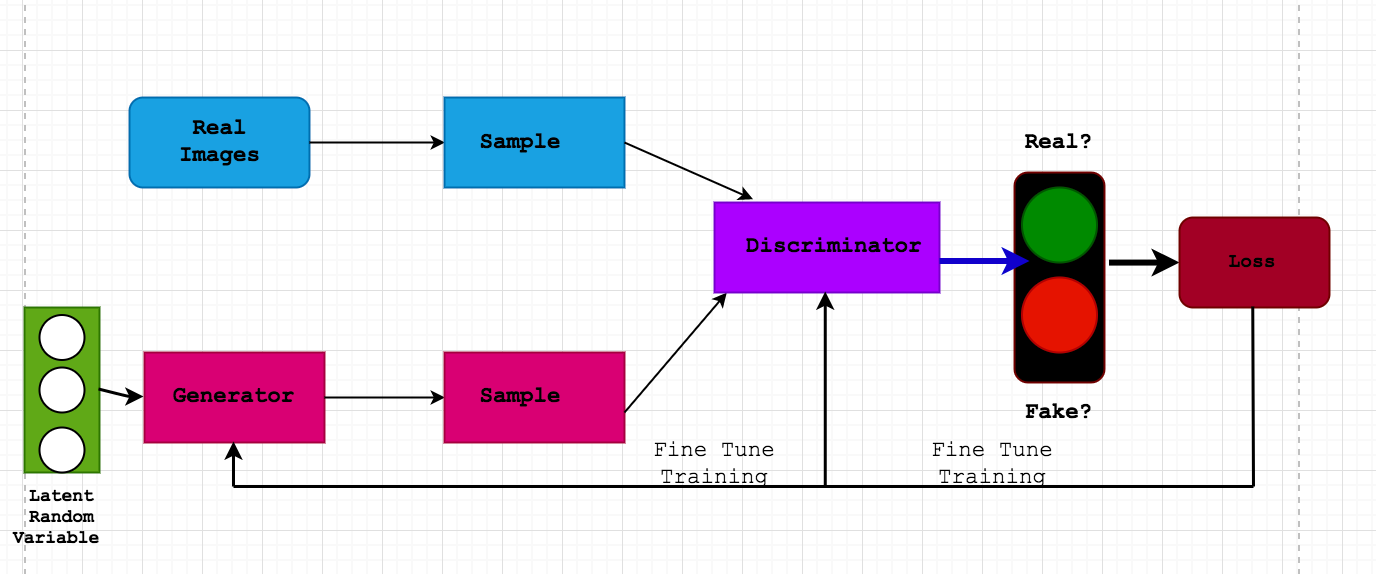
What is GAN Architecture?
Before delving into the specifics of GigaGAN, let’s first understand the fundamental concept of GAN architecture. A Generative Adversarial Network (GAN) consists of two neural networks, the generator and the discriminator, competing against each other in a zero-sum game framework. The generator creates synthetic data instances, while the discriminator’s role is to distinguish between the generated data and real data. The ultimate goal of GANs is to generate new, synthetic data that closely resembles a known data distribution. There are various types of GAN architectures, each with its unique features and applications. Some of the popular ones include Vanilla GAN, Conditional GAN (CGAN), Deep Convolutional GAN (DCGAN), CycleGAN, Generative Adversarial Text to Image Synthesis, and StyleGAN. These architectures have revolutionized fields such as medical imaging, fashion, art, and video games, enabling researchers and developers to generate new data and enhance the quality of existing data.
GigaGAN: A Breakthrough in Text-to-Image Synthesis
GigaGAN, an innovation in the field of GAN architectures, is specifically designed for text-to-image synthesis. This state-of-the-art model is the result of collaboration between researchers from POSTECH, CMU, and Adobe. Its primary objective is to generate ultra-high-definition images with 512 pixels in just 0.13 seconds. GigaGAN achieves this remarkable feat through its disentangled, continuous, and controllable latent space. The latent space of GigaGAN allows for smooth interpolation between prompts, enabling various latent space editing applications like latent interpolation, style mixing, and vector arithmetic operations. By combining the coarse style of one sample with the fine style of another, GigaGAN retains a disentangled latent space, enhancing its flexibility and generating visually stunning images.
Types of GAN Architectures
To better understand the unique features of GigaGAN, let’s explore some of the different types of GAN architectures:
Vanilla GAN
Vanilla GAN is the simplest form of GAN architecture. It comprises a generator and a discriminator, both implemented as multi-layer perceptrons. The algorithm behind vanilla GAN optimizes a mathematical equation using stochastic gradient descent.
Conditional GAN (CGAN)
A Conditional GAN (CGAN) incorporates additional information, such as class labels, into the generative process. This deep learning model provides more control over the output by conditioning the generation on specific input conditions.
Deep Convolutional GAN (DCGAN)
Deep Convolutional GAN (DCGAN) is one of the most popular and successful implementations of GAN. It replaces multi-layer perceptrons with ConvNets and utilizes convolutional stride instead of max pooling. The absence of fully connected layers further enhances its effectiveness.
CycleGAN
CycleGAN is a GAN architecture used for image-to-image translation tasks. It can learn to translate images from one domain to another without the need for paired training data. This makes it particularly useful in various domains such as artistic style transfer and domain adaptation.
Generative Adversarial Text to Image Synthesis
Generative Adversarial Text to Image Synthesis is a specialized GAN architecture designed for generating realistic images from textual descriptions. This model has shown immense potential in applications like computer vision and content generation.
StyleGAN
StyleGAN introduces a style-based generator architecture, enabling better disentanglement of high-level attributes and improved image quality at high resolutions. This innovation has significantly advanced the quality and realism of GAN-generated images.
GigaGAN: An Open-Source Model
One of the key advantages of GigaGAN is its open-source nature. The model has been implemented in PyTorch and is available on GitHub under the MIT License. This open-source implementation allows researchers and developers to use and modify GigaGAN for their own purposes, promoting collaboration, and fostering innovation in the field of text-to-image synthesis. The availability of GigaGAN as an open-source model also facilitates comparisons with other models and encourages researchers to build upon its successes. It serves as a benchmark for evaluating the performance of new text-to-image synthesis models and further propels advancements in the field.
Unique Features of GigaGAN
Compared to other GAN architectures, GigaGAN boasts several unique features that set it apart. Let’s explore these distinctions:
- Text-to-Image Synthesis: GigaGAN is specifically designed for text-to-image synthesis, differentiating it from architectures developed for other tasks like image-to-image translation or video generation.
- Disentangled Latent Space: GigaGAN’s disentangled, continuous, and controllable latent space allows for smooth interpolation between prompts. This feature enables various latent space editing applications, including latent interpolation, style mixing, and vector arithmetic operations.
- Ultra-High-Definition Image Generation: GigaGAN can generate ultra-high-definition images with 512 pixels in just 0.13 seconds. This exceptional speed distinguishes GigaGAN from other GAN architectures and opens up new possibilities for real-time image synthesis applications.
- Large Parameter Count: GigaGAN boasts an impressive 1 billion parameters, making it six times larger than the largest GAN architecture to date. This expansive parameter count contributes to GigaGAN’s ability to generate highly detailed and realistic images.
- Retained Disentangled Latent Space: GigaGAN enables the combination of coarse and fine styles from different samples, retaining a disentangled latent space. This capability enhances the flexibility and artistic expression of the generated images.
Conclusion
GigaGAN, a state-of-the-art GAN architecture developed by researchers from POSTECH, CMU, and Adobe, represents a significant breakthrough in the field of text-to-image synthesis. Its disentangled latent space, ultra-high-definition image generation capabilities, and open-source nature distinguish it from other GAN architectures. GigaGAN’s availability as an open-source model promotes collaboration, enables comparisons with other models, and facilitates advancements in text-to-image synthesis. With its unique features and applications, GigaGAN paves the way for further innovation and creativity in the realm of generative adversarial networks.

Humanoid robots are a type of professional service robot that are designed to resemble and interact with humans.
Aug 30, 2023 · 2 mins read

Few top upcoming trends in artificial intelligence
Aug 29, 2023 · 4 mins read

This blog explains about how AI Tools work
Sep 9, 2023 · 6 mins read

Best 10 AI tools similar to ChatGPT
Sep 9, 2023 · 4 mins read

As the field of artificial intelligence (AI) continues to advance at a rapid pace, open-source AI tools have become invaluable resources for developers and companies.
Sep 8, 2023 · 5 mins read
Best AI Tools for Website Design
Sep 7, 2023 · 6 mins read

Dive into the magic behind Spotify's AI, as it crafts playlists tuned to your mood. Explore how audio analysis, user behavior, and innovative tech converge to create a personalized music experience that resonates with every beat of your heart. Perfect for those curious about the fusion of technology and music.

Discover how Spotify's innovative AI playlist feature is changing the game for music lovers. Explore personalized soundscapes tailored to your taste with unmatched precision. Don't miss out on this musical revolution!

Explore the unexpected resurgence of analog computing in our digital era. This in-depth article delves into its unique advantages, modern applications, and future potential. Perfect for tech enthusiasts and history buffs alike, discover how analog computing is making a remarkable comeback!

Discover how AI is transforming web design! Unveiling the synergy of creativity and technology, this article explores AI's innovative tools and techniques in shaping user-friendly, aesthetically pleasing websites. Dive into the future of digital design now!

Dive into the world of advanced AI with our in-depth guide on the best alternatives to Midjourney AI. Discover cutting-edge tools that match your needs for innovation and efficiency.

Dive into the tech revolution with Apple's M3 Chip. Discover how its cutting-edge GPU advancements are setting new performance benchmarks.
Sharing is caring!